Excerpt from "Trillions: Thriving in the Emerging Information Ecology" by Peter Lucas,
Joe Ballay and Mickey McManus (Wiley, 2012). The authors are principals at MAYA
Design, one of America's top pervasive computing design firms.
There are already many more computing devices in the world than there are people. In a few more years, their number will climb into the trillions. Moreover, we are quickly figuring out how to make those processors communicate with each other, and with us. We are about to be faced with -- not a trillion isolated devices -- but a trillion-node network: a network whose scale and complexity will dwarf that of today's Internet. And, unlike the Internet, this will be a network not of computation that we use, but of computation that we live in.
Challenges in the Information Ecology
This book has two themes that are somewhat in tension. On one hand, we claim that the information ecology is upon us whatever we do or don't do. On the other hand, we say that it is critical to apply the principles of design science to guide its emergence. This may strike some readers as contradictory. But it is really just an example of the familiar tension between trusting our fate to self-determining, natural forces and centralized, rational efforts to bend such forces to our will. This is the tension underlying the conservative/liberal axis in politics; the subtle balance between free-market economics and government regulation. The skills involved are those of the surfer who sizes up patterns in a wave's unalterable energy and rides them toward her own goals. They are the skills of the entrepreneur with the insight to foresee a high-leverage branch-point in the chaotic but nonrandom processes of the marketplace and to capitalize upon it for self-profit and social progress.
In contemplating such a system, three goals stand out: resiliency, trust, and what we might call human rightness or perhaps felicitousness.
Resiliency
Every psychology student learns the story of the celebrated Phineas Gage, the nineteenth century railroad gandy dancer who, having had a 13-pound iron bar propelled directly through his brain by an ill-timed blast of powder, was able to speak and walk within a few minutes, and led a reasonably normal life for 12 more years. Gage did not escape wholly unscathed, but given the magnitude of his injuries, his recovery was striking.
Phineas Gage and his iron bar

Now, imagine an analogous amount of damage to a modern PC or smart-phone. No. Imagine a vastly smaller amount of damage -- say, some kind of microscopic lesion through the device's circuitry involving only a few hundred transistors. How would the device survive such damage? The chances are that it would not survive at all. It is a credit to modern engineering that we have learned how to make such fragile devices reliable. But they are not very resilient, which is a different thing entirely. The failure of any one of the billions of transistors in a modern CPU chip has a good chance of rendering the chip useless, so reliability of that CPU depends on the assumption that every transistor will work perfectly every time. An animal brain, on the other hand, has an architecture that makes no such assumption. Individual neurons are slow, noisy, and unreliable devices. And yet, a human brain is capable of functioning nonstop for a century or more, while sustaining serious abuse along the way.
We see from these examples that there are two different approaches to achieving robust systems: bottom-up ultrareliability, and top-down resiliency. The computer industry has so far mostly relied on the former. (The original architecture of the Internet being a notable exception.) But in the coming information ecology, this will not work. None of the techniques that have allowed manufacturers to make it work -- centrally controlled choices of components; uniform manufacturing environments; mass-replication of nearly identical vertically integrated systems; factory-level unit testing -- will characterize the age of Trillions. Creating large, complex systems will be less like factory manufacturing and more like growing a garden. One will plant, cultivate and prune -- not expecting every sprout to blossom.
Trust
Our willingness to embrace a technology or a source of information (and therefore their market viability) is completely dependent on our willingness to trust them. We fly in airliners because we trust that they will not fall out of the sky. We rely upon physical reference books found in the library because we trust that they are not elaborate forgeries and that their publishers have properly vetted their authors. But trust is a relative thing. We trust -- more or less -- well-known websites when we are shopping for appliances or gadgets. But we are more careful about things we read on the Internet when the consequences are high. We consider web-based sources of medical information, but we do so with caution. We tend to discount random political rants found on personal blogs. We trust not at all e-mail from widows of former Nigerian ministers of finance. Wikipedia has earned our trust for many routine purposes, but would we be willing to have our taxes calculated based upon numbers found there? Similarly, we trust consumer computing devices for surfing the web, for TiVo-ing our television programs, and perhaps for turning on our porch light every evening, but we do not trust them to drive our cars or to control our cities.
As these examples illustrate, our requirements for trust vary proportionately with the criticality of the applications. The average level of trust of the Internet or of consumer computing devices is fairly low, but this is acceptable since we do not yet use them for the things that really matter. This is about to change, and so the stakes with respect to trust are going up.
Where does trust in a technology come from? This is a question with many answers, but some obvious ones involve reputation, provenance, and security. Reputation is practically synonymous with trust itself. Other than personal experiences, which are inevitably limited, what basis do we have for forming trust besides reputation? But, there can be no reputation without provenance. An anonymous note scribbled on a wall can almost never be trusted, simply because we know so little about its origin. Similarly, material obtained from today's peer-to-peer file sharing services is inherently untrustworthy. There is, in general, no way of knowing whether a file is what it claims to be, or whether it has been subtly altered from its original. Which brings us, inevitably, to security. Our confidence in the provenance of an item in the real world depends critically on one of two things:
We believe that an object is what it seems to be either because it is technically difficult to duplicate, or because its history is accounted for. Dollar bills are an example of the former, and a fork once owned by George Washington might be an example of the latter.
As these examples suggest, most traditional approaches to security are tied to physical attributes such as complex structures of various kinds or brute-force barriers to entry. These familiar approaches have also formed the basis for the security of information systems in the great majority of cases. We protect the contents of our PCs by keeping strangers away from them. We keep our cell phones and our credit cards securely in our pockets and purses. Large corporations keep their data crown jewels locked away in data center fortresses.
The time will soon come however in which it will be necessary to almost completely abandon physical security as a component of our system of trust. In a world of immaterial, promiscuously replicated data objects, in which cyberspace itself will be implemented in a radically distributed manner, all secrets must be encrypted and most nonsecrets must be digitally signed. In this world, if you would not be willing to hand copies of your most important data to your mortal enemies (properly encrypted, of course), then any sense of security you may have will be illusory.
These issues of trust, provenance, reputation, and security don't apply only to information. In the age of Trillions, they will be equally important when dealing with physical devices. This is a relatively minor issue today. But, when every piece of bric-a-brac will have enough computing power to do real mischief, the provenance of trivial things will come to be of concern. Even today, how would you know if deep inside the CPU chip of your new Internet-connected TV there was some tiny bit of unnoticed logic -- the result of some secret mandate of some unscrupulous foreign government -- implementing a latent back-door trojan horse, waiting for an innocent-looking automatic firmware update to begin doing god-knows-what? Has such a thing ever been done? We have no idea. Is it implausible? Not in the least. There will soon be a great many places to hide, and malicious functionality hiding in insignificant hardware is going to be a whole lot more insidious than malicious code hiding in information objects. In the future, the provenance of mundane objects is going to become of real interest.
Felicitousness: Designing for People
The information ecology that we have been sketching involves a kind of automation, but it is not the automation of a lights-out robotically controlled factory. Far from being a system apart from humanity, it will be a seamless symbiosis between human and machine systems. In this respect, it is more like a home or a city than it is like a factory. This is a crucial point, because it gets to the heart of why pulling off the next 50 years is going to be a challenge. In a nutshell, the challenge is this: We are facing an engineering project as big as any that humanity has ever faced, but the system being engineered will be as much human as it is machine. The trick will be to insure that it is also humane.
At the time we are writing, the current next big thing is any Internet business plan containing the words social networking. This is just the latest in what will prove to be a long row of profit-making dominos that the industry will knock down. But it is a fortunate one at the present juncture, since it focuses the industry on the basic issues of human interaction, which is where the important developments are going to lie from now on.
Empowering Power Users
The early days of the PC were a classic case of a solution in search of a problem. It was pretty obvious that a computer-on-your-desk was an exciting prospect and had to be good for something. But what? Storing recipes perhaps? We were in a hunt for a killer app. When we finally found one in the late 1970s, it was at first a bit surprising. It turned out to be something called VisiCalc. VisiCalc was basically a glorified financial calculator, but it had two features that are critical to our story: first, it had an architecture. Better yet, it had an architecture tied to a good metaphor. The metaphor was that of a financial spreadsheet -- a grid of rows and columns forming cells. It was a simple, powerful concept that made sense to business users. Second -- and critically -- VisiCalc was scriptable. It wasn't so much an application as a box of Lego blocks. It did almost nothing out of the box, but it was relatively easy to build highly specific appliances that fit like a glove into the workflows of particular offices.
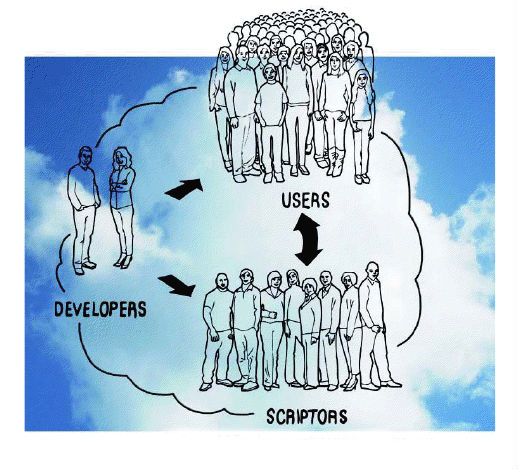
This story may strike you as being out of place in a section about social processes in pervasive computing. But the story is essentially social. To see why, we need to point out one more fact about spreadsheet programs: many users who routinely employ spreadsheets really don't understand them very well. Although developing new spreadsheet appliances is relatively easy when compared with writing a computer program from scratch, it is still a somewhat arcane process requiring certain specialized skills and a certain temperament. Most people prefer to just get on with their jobs. The true breakthrough of the spreadsheet program was that it empowered the former to support the latter. Many people would rather have a root canal than create an elaborate spreadsheet. But everybody knows the wizard down the hall who is great at it and loves the challenge. These aren't programmers, they are scriptors -- paraprogrammers.
This story of architecture empowering people to help each other in intimate local settings is of crucial importance in envisioning how the coming information ecology will operate. Both the sheer scale of the systems we will be deploying and their vast diversity and sensitivity to local conditions simply precludes any deployment and support system that does not have the essential characteristics of locality and interpersonal communications that is epitomized by the end-user/power-user axis. This is a fundamentally social process, but one that is enabled by subtle and deliberate design decisions by the device and information architects who conceive and cultivate the DNA of these new life-forms.
Developers serving scriptors serving users