
You see it in newspapers and magazines every day. "Miracle cure for xxx!" screams the headline. "Education program doubles student gains!"
Then the article underneath the headline describes a small study, say with 50 to 100 subjects or even fewer. The study authors are quoted saying how important this is and why they were surprised and pleased by the findings. If the authors want to express appropriate scientific caution, they then say something like, "Of course we'll want to see this replicated on a larger scale..." But this caveat appears near the end of the article when most readers have already gone on to the crossword puzzle.
Chances are, you'll never hear about this treatment again. If anyone does repeat the evaluation using a significantly larger sample size, the outcomes are almost certain to be far smaller than those in the small study.
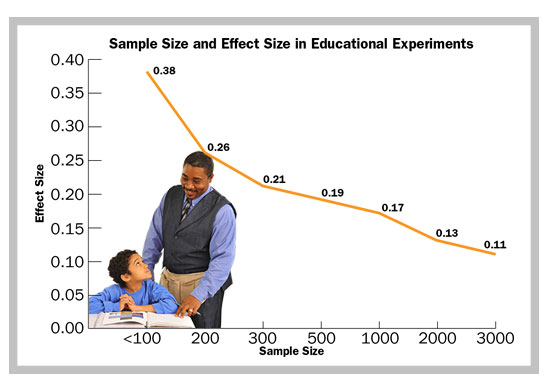
My colleague, Alan Cheung, and I have recently completed a large review of research on methodological features that influence the reported outcomes of experiments in education. We examined 645 studies of elementary and secondary math, reading, and science programs that met a stringent set of inclusion standards. The outcomes were astonishing. The smaller the study, the larger the effect size. The average effect size in studies with sample sizes of 100 or less was +0.38, while the average effect size for studies with at least 3000 studies was only +0.11.
Why were these differences so large? One reason is that in small studies, researchers are often able to provide a great deal of oversight to make sure the treatment is implemented perfectly, far better than would be possible in a large study. This is called the "super-realization effect."
Second, small studies are far more likely to use outcome measures made up by the researchers, and these tend to produce much higher effect sizes.
Third, when small studies find negative or zero effects, they tend to disappear, both because journals reject them and because researchers shelve them (the "file-drawer effect"). In contrast, a large study costs a lot of money and probably was done with a grant, so a report is more certain to be available regardless of the outcome.
Could the small study outcomes be the true outcomes, while the large study outcome is so small because it is difficult to ensure quality implementation at a large scale? Perhaps. But the smaller effect size is probably a lot closer to what would be seen in real life. Education is an applied field, and no one should be terribly interested in treatments that only work with small numbers of students.
Small studies are fine in a process of development, possibly showing that a given program has potential. However, before we can say that a program is ready for broad dissemination, we need to see it repeated in multiple experiments or in studies with many students. Big experiments are expensive and difficult, of course, but if we're serious about evidence-based reform, we'd better go big or go home!