
I judge my predictions on four major attributes: relevancy, timeliness, accuracy, and cost-effectiveness. I am very proud of my 2013 Oscar predictions, because they excelled in all four attributes: they predicted all 24 categories (and all combinations of categories), moved in real-time, were very accurate, and built on a scalable and flexible prediction model.
Relevancy is the only one of my major attributes that relies on the subjective input of stakeholders, rather than an objective measure; I relied on people with more domain specific information than myself about what I should predict and, after watching my first Oscar show from start to finish, it certainly felt that any relevant set of predictions should have all 24 categories.
Of the six major categories that fall into the standard set of predictions, only two, best supporting actor and actress, are scattered into the first 20 awards. The show does not get to the biggest four awards, best: picture, director, actor, and actress until well past 11:30 PM ET. If I were watching the Oscars casually with my family or friends I would certainly want information on all 24 categories to sustain interest throughout the telecast. Further, predictions in all 24 categories are necessary to predict the total quantity of awards won by any given movie.
The real-time nature of my predictions proved extremely interesting in both quantifying and understanding the major trends of the awards season; further, predictions that are created just before Oscar day, are not available to interested people during these earlier events. Both major trends that I illustrated the day before the Oscars played a big role on Oscar night: Argo's rise with the award show victories and Zero Dark Thirty's fall with the increased concern over its depiction of torture. A third trend is evident in both the major categories where Django Unchained competed. Winner of best supporting actor, Christoph Waltz, moved from a small 10 percent likelihood of victory at the start of the season to 40 percent on Oscar day, a hair behind Lincoln's Tommy Lee Jones. And, taking advantage of Zero Dark Thirty's fall, Django Unchained came from behind for a commanding lead in the prediction for best original screenplay by Oscar day.
The first judge of accuracy is the error; my error is meaningfully smaller than the best comparisons. A simple way to calculate the error is to take the mean of the squared error for each nominee, where the error is (1- probability of victory) for a winner and (0 - probability of victory) for a loser. A full set of predictions is 122, with 22 categories of 5, 1 category of 9, and 1 category of 3. My final predictions at 4 p.m. ET on Oscar day had a MSE of 0.067. One comparison is my earliest set of predictions, which had a MSE of 0.108; the error got smaller and smaller as the award shows and other information spread into my predictions. Nate Silver's FiveThirtyEight only predicted the big six categories and Mr. Silver provided prediction points, rather than probabilities. But, converting his predictions into probabilities by dividing each nominee's points by the sum of points in the category, he had a MSE of 0.075 for those six categories to my meaningfully smaller 0.056. A final comparison is with my only input that had all 24 categories; the Oscar day prediction of Betfair, the prediction market, has virtually the same error as mine. Which is why I also consider calibration.
The second judge of accuracy is the calibration; my calibration is very strong. The easiest way to check calibration is to chart the percentage of predictions that occur for bucketed groups of predictions (e.g., for all of my predictions around 20 percent, how many occur?). As you can see from the chart, when I made a prediction that was around 20 percent, around 20 percent of the predictions occurred. Admittedly, my gut was a little concerned with predictions like 99 percent for Life of Pi to win best visual effects or 97 percent for Les Miserables to win best sound mixing, but that is why I trust my data/models, not my gut. Betfair, which has nearly identical errors, is systematically under confident; while my predictions dance around the magical 45 degree line (i.e., perfect calibration line), 100 percent of Betfair prices that round to 50, 80, 90, and 100 occur, while prices that round to 70 occur 80 percent of the time.
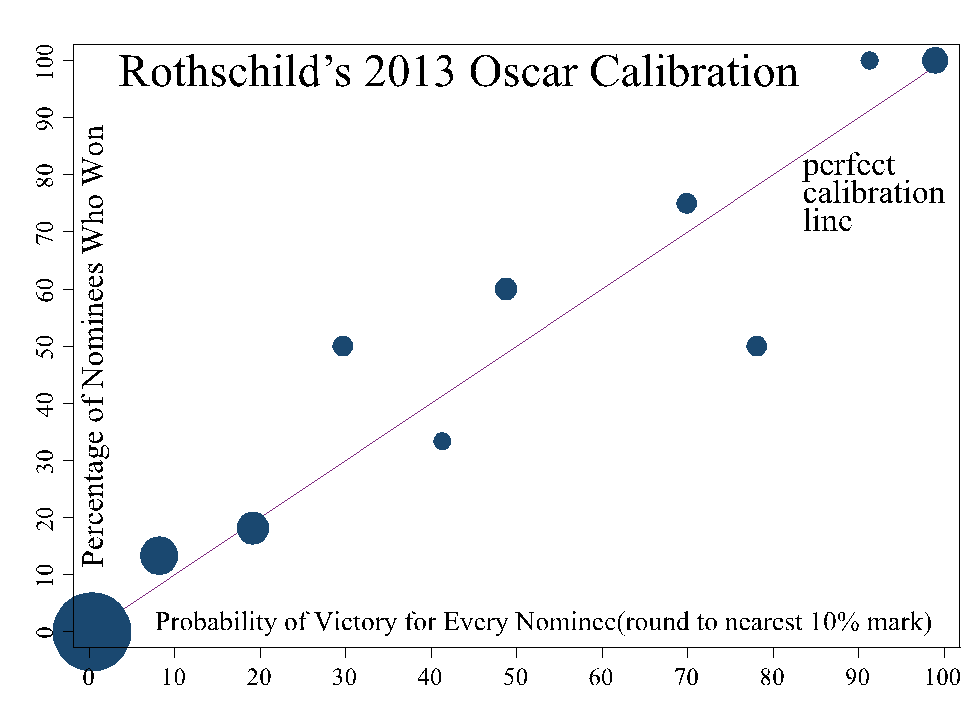
Sources: Betfair, Intrade, Hollywood Stock Exchange, PredictWise
The third judge of accuracy has to do with the models themselves and is not borne out in any one set of outcomes; is the prediction model robust for the future or over-fitted to the past and/or present. First, my models examine the historical data, but are carefully crafted using both in-sample and out-of-sample data to ensure they predict the future, rather than describe the past. Second, I always calibrate and release my models without any data from the current set of events. Models released too close to an event frequently suffer from inadvertent "look ahead-bias" where the forecaster, knowing what the other forecasters and his/her gut is saying, inadvertently massages the model to provide the prediction they want. That is why I release my models to run at the start of any season without ever checking what the current season's data will predict, before they are released.
The cost-effective nature of my modeling is the key to predicting all 24 categories. Along with traditional fundamental data, my model relies primarily on easily scalable data, like prediction markets and user-generated experimental data. It is scalable and cost-effective models/data that will eventually allow us to make incredible quantities of predictions in a wide-range of domains. Adding accuracy in an existing set of predictions like Best Actor or expected national vote-share in the presidential election is fun and could be meaningful, but creating accurate, real-time predictions in ranges of questions that could not exist before is the real challenge and goal of my work.
This column syndicates with my personal website: www.PredictWise.com.