Ockham's razor -- namely, that all other things being equal, simpler explanations are generally better than more complex ones -- has had a longstanding role in clinical medicine. The call for diagnostic parsimony is not to be viewed as a rule, simply as a good principle to regularly follow. But Ockham's razor is equally useful in the context of interpreting clinical research -- as exemplified by an analysis of the adequacy of randomization in the two randomized trials reporting the most pessimistic and optimistic findings about screening mammography.
Although both trials were initiated over three decades ago, both published long-term follow-up data in the last few years. After 25 follow-up, the Canadian National Breast Screening Study reported that screening mammography had no effect on breast cancer mortality. After 29 of follow-up, the Swedish Two-County Trial reported that screening mammography reduced breast cancer mortality by 31 percent -- a figure, which adjusting for the 85 percent attendance rate, would translate to an estimated breast cancer mortality reduction for those attending screening of 36 percent (≈0.31/0.85).
Case I -- Canada
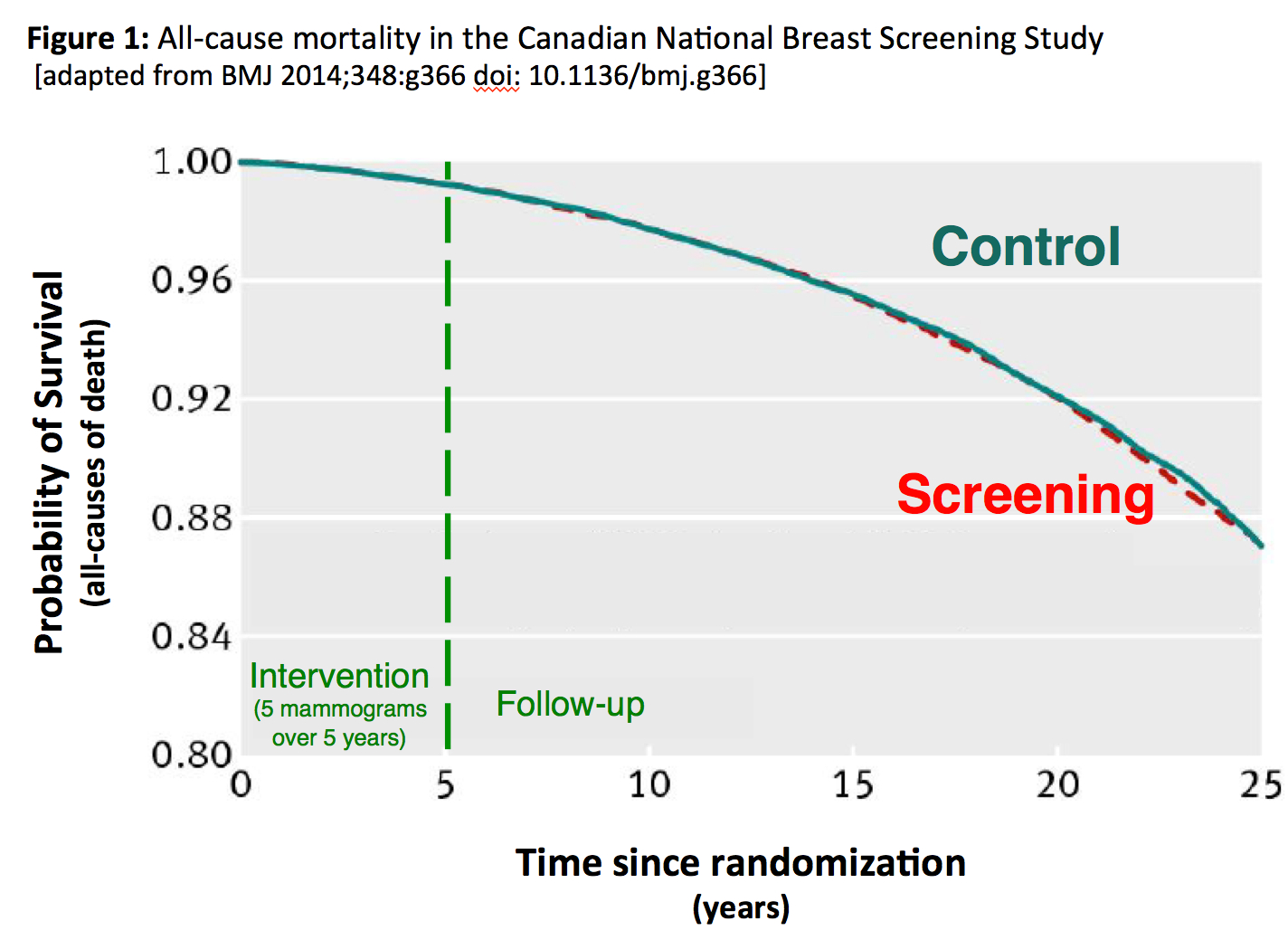
The Canadian National Breast Screening Study randomized 89,835 women to annual screening mammography or control. The study was initiated in 1980; the intervention period was five years. Since the initial publication of its findings in 1992, it has been the subject of intense criticism by a small group of physicians -- who appear to subscribe to the adage that if you repeat something often enough, it eventually becomes true. One criticism was the use of outdated mammographic technology, a concern that could be leveled at all the trials of screening mammography since they were initiated decades ago. The more serious criticism, however, was that the investigators had cheated: that randomization had been subverted and sicker women directed to the screening group. (When one of my 20-something-year-old MPH students parroted this concern last fall, it impressed me that the adage may well be correct.)
Although not its primary intent, Figure 1 from the long-term follow-up speaks to the question of the adequacy of randomization. Guided by Ockham's Razor readers can ask themselves which is the simpler explanation for the superimposition of the survival curves: a.) the 89,835 women were allocated into two groups via a random process or b.) randomization was subverted, yet the sicker women randomized to screening benefited just enough -- but not too much -- from the screening program to match their survival with the control group.
Case II: Swedish Two-County
The Swedish Two-County trial investigated screening mammography every 24 (age
Evaluation of the full impact of screening, in particular estimates of absolute benefit and number needed to screen, requires follow-up times exceeding 20 years because the observed number of breast cancer deaths prevented increases with increasing time of follow-up.
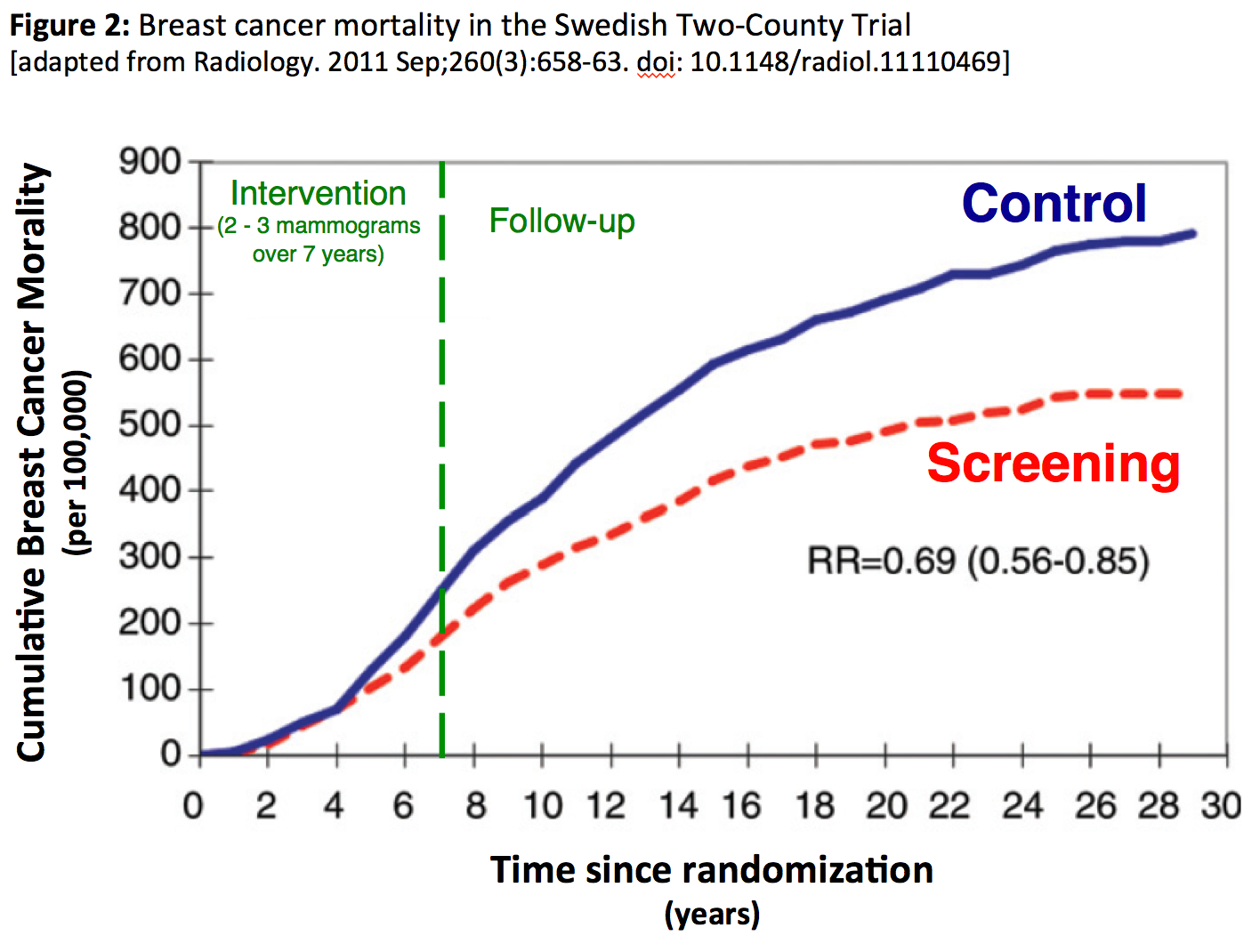
Although the Two-County trial included 133,065 women, the randomization was not at the level of individual. Instead 45 geographic clusters were randomized: 26 to screening and 19 to control. A similar randomization of clusters was used in the Edinburgh trial of screening mammography (87 physician practices). Because all-cause mortality was 20 percent lower in the group randomized to screening, everyone agrees that randomization failed and thus Edinburgh is routinely excluded in meta-analyses of screening mammography.
Again, although not its primary intent, Figure 2 from the long-term follow-up of the Two-Country trial speaks to the question of the adequacy of randomization. Guided by Ockham's Razor readers can ask themselves which is the simpler explanation for the growing divergence between the two curves: a.) the randomization of 45 geographic clusters failed to produce otherwise equivalent groups of women or b.) the cluster randomization produced equivalent groups and that the beneficial effect of two or three mammograms continues to increase over 20 years after they are obtained.
Of course, there is more complexity to the randomized trials of screening mammography. The intervention in the Canadian trial was actual screening, while the intervention in the Two-County was invitation to screening. The Canadian trial involved two mammographic views, while the Two-County involved only one. The Canadian trial included a standardized clinical breast exam for women age 50 and older in both the intervention and control groups, while the Two-County did not.
Furthermore, all the mammography trials are messier than any of us would like. They involve tens of thousands of women, who -- because they are well -- are not particularly connected with the medical care system. Not surprisingly, they are hard to keep track of, particularly over the years of follow-up required. Its hard enough when women have volunteered for the trial (Canada), imagine the challenge of following those who are unaware they are even in a trial (in Two-County, those who choose not to respond to the screening invitation and those who served as passive controls). Add to that the challenges in ascertaining the primary outcome -- breast cancer death -- not to mention the question of how to identify treatment-related mortality.
And then there is the general question of how applicable any of the screening trials are given that they largely predate tremendous advances in breast cancer therapy. The better we are able to treat clinical disease, the less important early detection becomes. But how we interpret the original trials can have a profound effect on how we view new data. In short, priors matter. Ockham's razor -- the principle of parsimony -- has always been less about refuting the complex and more about shifting the burden of proof. The value of searching for breast cancers that are too small to feel is one aspect of medical care that would benefit from such a shift.