

Ever since Gene Glass popularized the effect size in the 1970s, readers of research have wanted to know how large an effect size has to be in order to be considered important. Well, stop the presses and sound the trumpet. I am about to tell you.
First let me explain what an effect size is and why you should care. An effect size sums up the difference between an experimental (treatment) group and a control group. It is a fraction in which the numerator is the posttest difference on a given measure, adjusted for pretests and other important factors, and the denominator is the unadjusted standard deviation of the control group or the whole sample. Here is the equation in symbols.
![]()
What is cool about effect sizes is that they can standardize the findings on all relevant measures. This enables researchers to compare and average effects across all sorts of experiments all over the world. Effect sizes are averaged in meta-analyses that combine the findings of many experiments and find trends that might not be easy to find just looking at experiments one at a time.
Are you with me so far?
One of the issues that has long puzzled readers of research is how to interpret effect sizes. When are they big enough to matter for practice? Researchers frequently cite statistician Jacob Cohen, who defined an effect size of +0.20 as "small," +0.50 as "moderate," and +0.80 as "strong." However, Bloom, Hill, Black, & Lipsey (2008) claim that Cohen never really supported these criteria. New Zealander John Hattie publishes numerous reviews of reviews of research, and routinely finds effect sizes of +0.80 or more, and in fact suggests that educators ignore any teaching method with an average effect size of +0.40 or less. Yet Hattie includes literally everything in his meta-meta analyses, including studies with no control groups, studies in which the control group never saw the content assessed by the posttest, and so on. In studies that do have control groups and in which experimental and control groups were tested on material they were both taught, effect sizes as large as +0.80, or even +0.40, are very unusual, even in evaluations of one-to-one tutoring by certified teachers.
So what's the right answer? The answer turns out to mainly depend on just two factors: Sample size, and whether or not students, classes/teachers, or schools were randomly assigned (or assigned by matching) to treatment and control groups. We recently did a review of twelve published meta-analyses including only the 611 studies that met the stringent inclusion requirements of our Best-Evidence Encyclopedia (BEE). (In brief, the BEE requires well-matched or randomized control groups and measures not made up by the researchers.) The average effect sizes in the four cells formed by quasi-experimental/randomized and small/large sample size (splitting at n=250) are as follows.
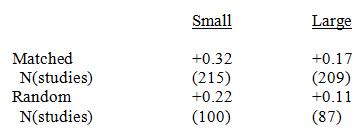
Here is what this chart means. If you look at a study that meets BEE standards and students were matched before being (non-randomly) assigned to treatment and control groups, then the average effect size is +0.32. Studies that use the same sample sizes and design would need to reach an effect size like this to be at the average. In contrast, if you find a large randomized study, it will need an effect size of only +0.11 to be considered average for its type. If Program A reports an effect size of +0.20 and Program B reports the same, are the programs equally effective? Not if they used different designs. If Program A used a large randomized study design and Program B a small quasi-experiment, then Program A is a leader in its class and Program B is a laggard.
This chart only applies to studies that meet our BEE standards, which removes a lot of the awful research that gives Hattie the false impression that everything works, and fabulously.
Using the average of all studies of a given type is not a perfect way to determine what is a large or small effect size, because this method only deals with methodology. It's sort of "grading on a curve" by comparing effect sizes to their peers, rather than using a performance criterion. But I'd argue that until something better comes along, this is as good a way as any to say which effect sizes are worth paying attention to, and which are less important.